Artificial Intelligence
How does Retrieval Augmented Generation (RAG) work?
Part 2: The inner workings of Retrieval Augmented Generation (RAG)
If you read part 1 of this series, or you are already familiar with the fundamentals of LLMs, we are ready to attack our next topic: how does a RAG work?

RAG helps us efficiently search through large amounts of poorly structured data
Deriving new functionalities of LLMs by simply injecting new data and information into prompts, without the need to fine-tune models, is a huge leap forward in how we build and interact with AI systems. But it, too, has its limitations:
- The amount of text you can feed into a prompt is finite. Modern LLMs such as GPT-5 and Gemini allow you to feed an entire book into the input, but nonetheless, there is a limit.
- Simply feeding more and more data into the input means that the model (just like a human) will have a harder time to find what is relevant and what is not. Even if you could feed an infinite amount of data into the input, the quality of the output would decrease.
RAGs address both of these issues.
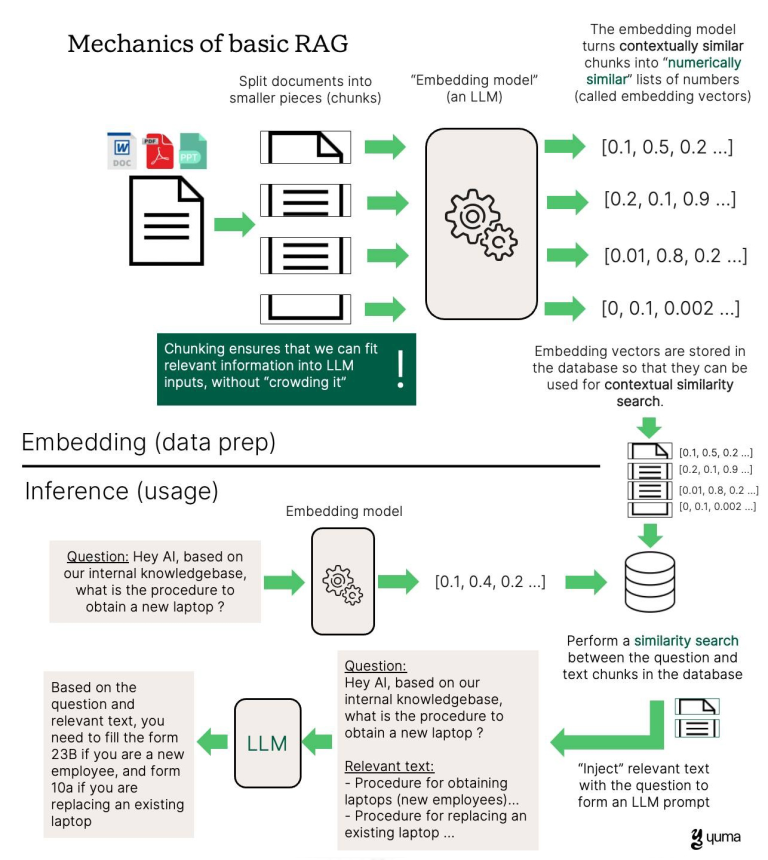
The basic idea behind a RAG is that before you construct an input for an LLM, you perform a search for relevant information, based on the original query. Think of it as a very sophisticated search engine which can say: “For this question, only the following documents are relevant.”
But how does it do that?
Compared to traditional keyword searches, “basic” RAGs can also match relevant data sources with the question in a context aware fashion. They do this by using LLMs themselves to convert data sources into lists of numbers (called embedding vectors) which capture not only the content, but the context of the text. Then, if I have an embedding vector for a question, and embedding vectors for all the textual chunks in my knowledge base, we have a way to numerically evaluate the relevance of each chunk of text in my knowledge base to the question at hand.
How this is done in detail depends on a bit of basic linear algebra, but all you need to know is that if I have two lists of numbers, I by definition have a way to numerically evaluate how “similar” they are. For computers, this is enough.
In other words, RAGs provide an efficient way to filter huge knowledge bases for only the contextually relevant parts. This improves the chances that we will be able to fit the relevant information into the input window of the LLM, as well as that the LLM won’t get confused by “noise”.
RAG explained
And here is another kicker: traditional search methods almost always require some underlying structure in the data, either some system of labels or data indexing. For example, you would label files by topics or group them into folders by client etc.
However, for most organisations, this is not a reality. There are still massive amounts of messy Sharepoints and other filestores of poorly structured data and unlabeled data (i.e. text, scanned images, …).
The value contained in those documents is the opportunity RAGs can now help you tap into!
The nice thing is that LLMs and RAGs don’t really care about data structure. Remember the embedding vectors I mentioned above? Any piece of text or an image can be turned into an embedding vector. The LLM doesn’t care, as long as it fits into the allowed input size. RAGs hence give us an unprecedented ability to sift through massive amounts of previously underutilised data and this represents by far the most common use case for RAG systems today.
Here are some examples:
- Customer Support Knowledge Base: A RAG can search through manuals, FAQs, and troubleshooting documents, then generate a tailored answer for a customer’s query. For example, a user asks, “Why is my printer flashing red?”, and the RAG system retrieves relevant sections from the printer’s support documentation and provides a clear, synthesized fix.
- Legal Document Analysis: Lawyers can use RAG to query large corpora of case law, statutes, and contracts to find precedent or clauses relevant to a matter. For example, a lawyer asks, “What precedents are there for breach of confidentiality in UK law?”. The RAG model retrieves matching case summaries and creates a concise overview.
- Scientific Research Assistance: Researchers can feed in academic papers, technical reports, and datasets so RAG can answer specific scientific questions. A biologist can ask, for example:“What’s the latest research on CRISPR off-target effects in mammalian cells?” The system can retrieve recent studies and summarize them with citations.
- Enterprise Data Access: Employees can query internal company documents, wikis, and reports without knowing exactly where to look. For instance, a project manager can ask: “What was the final budget allocation for Project Horizon?” The RAG system retrieves the final finance report and extracts the relevant numbers.
- Codebase Search for Developers: Developers can search large code repositories to find implementation patterns or fix bugs. A programmer could ask: “Where do we handle JWT token verification?” and the RAG would retrieve the relevant function definitions and related comments from the repository, then explain how it works.
Building a RAG is easy. Building a RAG that works is not.
There are several reasons for this: the RAG technology has been standardized into numerous frameworks which can be used almost out of the box, significantly cutting on the development time and reducing CAPEX associated with building RAG systems.
However, ensuring that your RAG will return relevant information (i.e. an optimal retrieval strategy) remains to be a bit of an art form. The way you contextualise legal questions may be very different from the way you contextualise technical documentation of a piece of software. Hence, the way you retrieve the information from your database may need to be different as well. Does the LLM you use to produce embedding vectors capture this well? If not, which other LLM should you use? Should I use a combination of contextual and keyword search? Or perhaps something even more sophisticated?
Getting the retrieval step of a RAG to work well is by far the biggest challenge in all RAG systems. It often requires iterative progress where user feedback on the answer quality is evaluated against various (or a combination of) retrieval strategies. The good news is that it’s a topic which has been studied so much that we have a lot of tools to make it work at our disposal. Matching the right ones with the use case at hand is where the real work lies.
In addition, evaluating the performance of a RAG in an automated fashion is difficult. The reason is simple: it is producing context dependent results where the context is user specific. Hence, the user remains in the best position to evaluate the quality of the answer.
Agentic AI supercharges the RAGs.
When people talk about Agentic AI, what they really mean is that LLMs can use (and choose when to use) digital tools. RAG can be one of the tools that’s available to an LLM, allowing Agentic AI to combine several relevant information from multiple sources before constructing an answer.
Let’s say that you want to produce a market report on Avenger themed toys. It’s a complex document depending on a wealth of potential data sources. Agentic AI systems can accomplish this task by accessing different types of data via digital tools. For example, your internal knowledge base (accessible via a RAG tool) may contain past market reports which will provide historical context. An LLM could use a web browser (another tool) to search Amazon and collect information about pricing of the Avenger themed toys. A web search tool could collect publicly available information and news about companies which are producing Avenger themed toys etc. All of this information would provide a much fuller context to the LLM to write a report, compared to, say, a single source.
RAGs have become an integral part and in some cases a backbone of multi-agent systems where collaboration between different AI agents, their tools and humans serves to meet a common objective. Through careful division of roles and labour, we can orchestrate hybrid teams to leverage RAGs for easy access to relevant information, without the need for complex, resource intensive model fine-tuning.
Enjoyed this insight?
Share it to your network.

Mihailo Backovic
Ready to start shaping the business of tomorrow?
[email]
